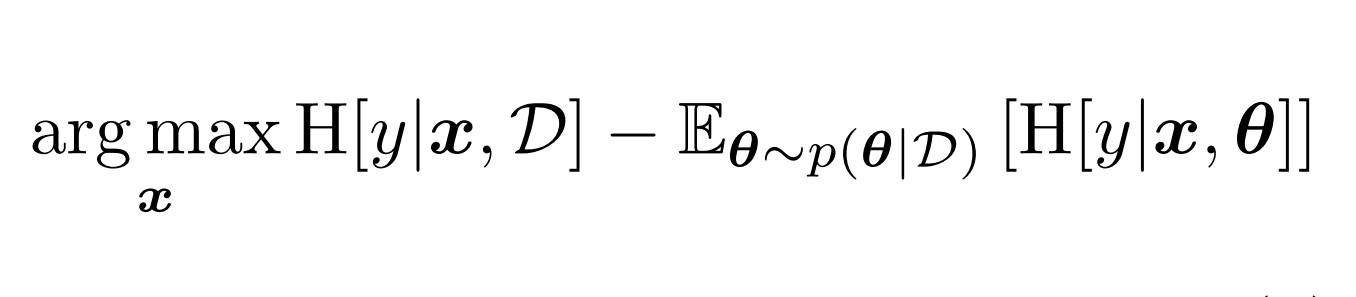1. Frozen Feature Augmentation for Few-Shot Image Classification
Authors: Andreas Bär, Neil Houlsby, Mostafa Dehghani, Manoj Kumar
First appeared: 2024-03-15
Venue: Computer Vision and Pattern Recognition (CVPR), 2024
Full paper
► Abstract
Training a linear classifier or lightweight model on top of pretrained vision model outputs, so-called 'frozen features', leads to impressive performance on a number of downstream few-shot tasks. Currently, frozen features are not modified during training. On the other hand, when networks are trained directly on images, data augmentation is a standard recipe that improves performance with no substantial overhead. In this paper, we conduct an extensive pilot study on few-shot image classification that explores applying data augmentations in the frozen feature space, dubbed 'frozen feature augmentation (FroFA)', covering twenty augmentations in total. Our study demonstrates that adopting a deceptively simple pointwise FroFA, such as brightness, can improve few-shot performance consistently across three network architectures, three large pretraining datasets, and eight transfer datasets.
2. Gemini: A Family of Highly Capable Multimodal Models
Authors: Gemini Team Google
First appeared: 2023-12-19
Venue: arXiv, 2023
Full paper
► Abstract
This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
3. Scaling Laws for Sparsely-Connected Foundation Models
Authors: Elias Frantar, Carlos Riquelme, Neil Houlsby, Dan Alistarh, Utku Evci
First appeared: 2023-09-15
Venue: International Conference on Learning Representations (ICLR), 2024 [spotlight]
Full paper
► Abstract
We explore the impact of parameter sparsity on the scaling behavior of Transformers trained on massive datasets (i.e., "foundation models"), in both vision and language domains. In this setting, we identify the first scaling law describing the relationship between weight sparsity, number of non-zero parameters, and amount of training data, which we validate empirically across model and data scales; on ViT/JFT-4B and T5/C4. These results allow us to characterize the "optimal sparsity", the sparsity level which yields the best performance for a given effective model size and training budget. For a fixed number of non-zero parameters, we identify that the optimal sparsity increases with the amount of data used for training. We also extend our study to different sparsity structures (such as the hardware-friendly n:m pattern) and strategies (such as starting from a pretrained dense model). Our findings shed light on the power and limitations of weight sparsity across various parameter and computational settings, offering both theoretical understanding and practical implications for leveraging sparsity towards computational efficiency improvements.
4. From Sparse to Soft Mixtures of Experts
Authors: Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby
First appeared: 2023-08-23
Venue: International Conference on Learning Representations (ICLR), 2024 [spotlight]
Full paper
► Abstract
Sparse mixture of expert architectures (MoEs) scale model capacity without large increases in training or inference costs. Despite their success, MoEs suffer from a number of issues: training instability, token dropping, inability to scale the number of experts, or ineffective finetuning. In this work, we proposeSoft MoE, a fully-differentiable sparse Transformer that addresses these challenges, while maintaining the benefits of MoEs. Soft MoE performs an implicit soft assignment by passing different weighted combinations of all input tokens to each expert. As in other MoE works, experts in Soft MoE only process a subset of the (combined) tokens, enabling larger model capacity at lower inference cost. In the context of visual recognition, Soft MoE greatly outperforms standard Transformers (ViTs) and popular MoE variants (Tokens Choice and Experts Choice). For example, Soft MoE-Base/16 requires 10.5x lower inference cost (5.7x lower wall-clock time) than ViT-Huge/14 while matching its performance after similar training. Soft MoE also scales well: Soft MoE Huge/14 with 128 experts in 16 MoE layers has over 40x more parameters than ViT Huge/14, while inference time cost grows by only 2%, and it performs substantially better.
5. Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
Authors: Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim Alabdulmohsin, Avital Oliver, Piotr Padlewski, Alexey Gritsenko, Mario Lučić, Neil Houlsby
First appeared: 2023-07-12
Venue: Neural Information Processing Systems (NeurIPS), 2023
Full paper
► Abstract
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been successfully challenged. However, models such as the Vision Transformer (ViT) offer flexible sequence-based modeling, and hence varying input sequence lengths. We take advantage of this with NaViT (Native Resolution ViT) which uses sequence packing during training to process inputs of arbitrary resolutions and aspect ratios. Alongside flexible model usage, we demonstrate improved training efficiency for large-scale supervised and contrastive image-text pretraining. NaViT can be efficiently transferred to standard tasks such as image and video classification, object detection, and semantic segmentation and leads to improved results on robustness and fairness benchmarks. At inference time, the input resolution flexibility can be used to smoothly navigate the test-time cost-performance trade-off. We believe that NaViT marks a departure from the standard, CNN-designed, input and modelling pipeline used by most computer vision models, and represents a promising direction for ViTs.
6. Scaling Open-Vocabulary Object Detection
Authors: Scaling Open-Vocabulary Object Detection
First appeared: 2023-06-16
Venue: Neural Information Processing Systems (NeurIPS), 2022 [spotlight]
Full paper
► Abstract
Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can be expanded by using Web image-text pairs as weak supervision, this has not been done at scales comparable to image-level pretraining. Here, we scale up detection data with self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. Major challenges in scaling self-training are the choice of label space, pseudo-annotation filtering, and training efficiency. We present the OWLv2 model and OWL-ST self-training recipe, which address these challenges. OWLv2 surpasses the performance of previous state-of-the-art open-vocabulary detectors already at comparable training scales (~10M examples). However, with OWL-ST, we can scale to over 1B examples, yielding further large improvement: With an L/14 architecture, OWL-ST improves AP on LVIS rare classes, for which the model has seen no human box annotations, from 31.2% to 44.6% (43% relative improvement). OWL-ST unlocks Web-scale training for open-world localization, similar to what has been seen for image classification and language modelling.
7. Image Captioners Are Scalable Vision Learners Too
Authors: Michael Tschannen, Manoj Kumar, Andreas Steiner, Xiaohua Zhai, Neil Houlsby, Lucas Beyer
First appeared: 2023-06-13
Venue: Neural Information Processing Systems (NeurIPS), 2023 [oral]
Full paper
► Abstract
Contrastive pretraining on image-text pairs from the web is one of the most popular large-scale pretraining strategies for vision backbones, especially in the context of large multimodal models. At the same time, image captioning on this type of data is commonly considered an inferior pretraining strategy. In this paper, we perform a fair comparison of these two pretraining strategies, carefully matching training data, compute, and model capacity. Using a standard encoder-decoder transformer, we find that captioning alone is surprisingly effective: on classification tasks, captioning produces vision encoders competitive with contrastively pretrained encoders, while surpassing them on vision & language tasks. We further analyze the effect of the model architecture and scale, as well as the pretraining data on the representation quality, and find that captioning exhibits the same or better scaling behavior along these axes. Overall our results show that plain image captioning is a more powerful pretraining strategy than was previously believed.
8. PaLI-X: On Scaling up a Multilingual Vision and Language Model
Authors: Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, Siamak Shakeri, Mostafa Dehghani, Daniel Salz, Mario Lucic, Michael Tschannen, Arsha Nagrani, Hexiang Hu, Mandar Joshi, Bo Pang, Ceslee Montgomery, Paulina Pietrzyk, Marvin Ritter, AJ Piergiovanni, Matthias Minderer, Filip Pavetic, Austin Waters, Gang Li, Ibrahim Alabdulmohsin, Lucas Beyer, Julien Amelot, Kenton Lee, Andreas Peter Steiner, Yang Li, Daniel Keysers, Anurag Arnab, Yuanzhong Xu, Keran Rong, Alexander Kolesnikov, Mojtaba Seyedhosseini, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, Radu Soricut
First appeared: 2023-05-29
Venue: Computer Vision and Pattern Recognition (CVPR), 2024
Full paper
► Abstract
We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
9. Scaling Vision Transformers to 22 Billion Parameters
Authors: Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd van Steenkiste, Gamaleldin F. Elsayed, Aravindh Mahendran, Fisher Yu, Avital Oliver, Fantine Huot, Jasmijn Bastings, Mark Patrick Collier, Alexey Gritsenko, Vighnesh Birodkar, Cristina Vasconcelos, Yi Tay, Thomas Mensink, Alexander Kolesnikov, Filip Pavetić, Dustin Tran, Thomas Kipf, Mario Lučić, Xiaohua Zhai, Daniel Keysers, Jeremiah Harmsen, Neil Houlsby
First appeared: 2023-02-10
Venue: International Conference on Machine Learning (ICML), 2023 [oral]
Full paper
► Abstract
The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
10. Dual PatchNorm
Authors: Manoj Kumar, Mostafa Dehghani, Neil Houlsby
First appeared: 2023-02-02
Venue: Transactions on Machine Learning Research (TMLR)
Full paper
► Abstract
We propose Dual PatchNorm: two Layer Normalization layers (LayerNorms), before and after the patch embedding layer in Vision Transformers. We demonstrate that Dual PatchNorm outperforms the result of exhaustive search for alternative LayerNorm placement strategies in the Transformer block itself. In our experiments, incorporating this trivial modification, often leads to improved accuracy over well-tuned Vision Transformers and never hurts.
11. Adaptive Computation with Elastic Input Sequence
Authors: Fuzhao Xue, Valerii Likhosherstov, Anurag Arnab, Neil Houlsby, Mostafa Dehghani, Yang You
First appeared: 2023-01-30
Venue: International Conference on Machine Learning (ICML), 2023
Full paper
► Abstract
Humans have the ability to adapt the type of information they use, the procedure they employ, and the amount of time they spend when solving problems. However, most standard neural networks have a fixed function type and computation budget regardless of the sample's nature or difficulty. Adaptivity is a powerful paradigm as it not only imbues practitioners with flexibility pertaining to the downstream usage of these models but can also serve as a powerful inductive bias for solving certain challenging classes of problems. In this work, we introduce a new approach called AdaTape, which allows for dynamic computation in neural networks through adaptive tape tokens. AdaTape utilizes an elastic input sequence by equipping an architecture with a dynamic read-and-write tape. Specifically, we adaptively generate input sequences using tape tokens obtained from a tape bank which can be either trainable or derived from input data. We examine the challenges and requirements to obtain dynamic sequence content and length, and propose the Adaptive Tape Reading (ATR) algorithm to achieve both goals. Through extensive experiments on image recognition tasks, we show that AdaTape can achieve better performance while maintaining the computational cost. To facilitate further research, we have released code at https://github.com/google-research/scenic.
12. Massively Scaling Heteroscedastic Classifiers
Authors: Mark Collier, Rodolphe Jenatton, Basil Mustafa, Neil Houlsby, Jesse Berent, Effrosyni Kokiopoulou
First appeared: 2023-01-30
Venue: International Conference on Learning Representations (ICLR), 2023
Full paper
► Abstract
Heteroscedastic classifiers, which learn a multivariate Gaussian distribution over prediction logits, have been shown to perform well on image classification problems with hundreds to thousands of classes. However, compared to standard classifiers, they introduce extra parameters that scale linearly with the number of classes. This makes them infeasible to apply to larger-scale problems. In addition heteroscedastic classifiers introduce a critical temperature hyperparameter which must be tuned. We propose HET-XL, a heteroscedastic classifier whose parameter count when compared to a standard classifier scales independently of the number of classes. In our large-scale settings, we show that we can remove the need to tune the temperature hyperparameter, by directly learning it on the training data. On large image classification datasets with up to 4B images and 30k classes our method requires 14X fewer additional parameters, does not require tuning the temperature on a held-out set and performs consistently better than the baseline heteroscedastic classifier. HET-XL improves ImageNet 0-shot classification in a multimodal contrastive learning setup which can be viewed as a 3.5 billion class classification problem.
13. CLIPPO: Image-and-Language Understanding from Pixels Only
Authors: Michael Tschannen, Basil Mustafa, Neil Houlsby
First appeared: 2022-12-15
Venue: Computer Vision and Pattern Recognition (CVPR), 2023
Full paper
► Abstract
Multimodal models are becoming increasingly effective, in part due to unified components, such as the Transformer architecture. However, multimodal models still often consist of many task- and modality-specific pieces and training procedures. For example, CLIP (Radford et al., 2021) trains independent text and image towers via a contrastive loss. We explore an additional unification: the use of a pure pixel-based model to perform image, text, and multimodal tasks. Our model is trained with contrastive loss alone, so we call it CLIP-Pixels Only (CLIPPO). CLIPPO uses a single encoder that processes both regular images and text rendered as images. CLIPPO performs image-based tasks such as retrieval and zero-shot image classification almost as well as CLIP-style models, with half the number of parameters and no text-specific tower or embedding. When trained jointly via image-text contrastive learning and next-sentence contrastive learning, CLIPPO can perform well on natural language understanding tasks, without any word-level loss (language modelling or masked language modelling), outperforming pixel-based prior work. Surprisingly, CLIPPO can obtain good accuracy in visual question answering, simply by rendering the question and image together. Finally, we exploit the fact that CLIPPO does not require a tokenizer to show that it can achieve strong performance on multilingual multimodal retrieval without modifications.
14. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
Authors: Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, Neil Houlsby
First appeared: 2022-12-09
Venue: International Conference on Learning Representations (ICLR), 2023
Full paper
► Abstract
Training large, deep neural networks to convergence can be prohibitively expensive. As a result, often only a small selection of popular, dense models are reused across different contexts and tasks. Increasingly, sparsely activated models, which seek to decouple model size from computation costs, are becoming an attractive alternative to dense models. Although more efficient in terms of quality and computation cost, sparse models remain data-hungry and costly to train from scratch in the large scale regime. In this work, we propose sparse upcycling -- a simple way to reuse sunk training costs by initializing a sparsely activated Mixture-of-Experts model from a dense checkpoint. We show that sparsely upcycled T5 Base, Large, and XL language models and Vision Transformer Base and Large models, respectively, significantly outperform their dense counterparts on SuperGLUE and ImageNet, using only ~50% of the initial dense pretraining sunk cost. The upcycled models also outperform sparse models trained from scratch on 100% of the initial dense pretraining computation budget.
15. Location-Aware Self-Supervised Transformers for Semantic Segmentation
Authors: Mathilde Caron, Neil Houlsby, Cordelia Schmid
First appeared: 2022-12-05
Venue: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023 [oral]
Full paper
► Abstract
Pixel-level labels are particularly expensive to acquire. Hence, pretraining is a critical step to improve models on a task like semantic segmentation. However, prominent algorithms for pretraining neural networks use image-level objectives, e.g. image classification, image-text alignment a la CLIP, or self-supervised contrastive learning. These objectives do not model spatial information, which might be sub-optimal when finetuning on downstream tasks with spatial reasoning. In this work, we pretrain network with a location-aware (LOCA) self-supervised method which fosters the emergence of strong dense features. Specifically, we use both a patch-level clustering scheme to mine dense pseudo-labels and a relative location prediction task to encourage learning about object parts and their spatial arrangements. Our experiments show that LOCA pretraining leads to representations that transfer competitively to challenging and diverse semantic segmentation datasets.
16. Transcending Scaling Laws with 0.1% Extra Compute
Authors: Yi Tay, Jason Wei, Hyung Won Chung, Vinh Q. Tran, David R. So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, Denny Zhou, Donald Metzler, Slav Petrov, Neil Houlsby, Quoc V. Le, Mostafa Dehghani
First appeared: 2022-10-20
Venue: Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
Full paper
► Abstract
Scaling language models improves performance but comes with significant computational costs. This paper proposes UL2R, a method that substantially improves existing language models and their scaling curves with a relatively tiny amount of extra compute. The key idea is to continue training a state-of-the-art large language model (e.g., PaLM) on a few more steps with UL2's mixture-of-denoiser objective. We show that, with almost negligible extra computational costs and no new sources of data, we are able to substantially improve the scaling properties of large language models on downstream metrics. In this paper, we continue training PaLM with UL2R, introducing a new set of models at 8B, 62B, and 540B scale which we call U-PaLM. Impressively, at 540B scale, we show an approximately 2x computational savings rate where U-PaLM achieves the same performance as the final PaLM 540B model at around half its computational budget (i.e., saving ∼4.4 million TPUv4 hours). We further show that this improved scaling curve leads to 'emergent abilities' on challenging BIG-Bench tasks -- for instance, U-PaLM does much better than PaLM on some tasks or demonstrates better quality at much smaller scale (62B as opposed to 540B). Overall, we show that U-PaLM outperforms PaLM on many few-shot setups, i.e., English NLP tasks (e.g., commonsense reasoning, question answering), reasoning tasks with chain-of-thought (e.g., GSM8K), multilingual tasks (MGSM, TydiQA), MMLU and challenging BIG-Bench tasks. Finally, we provide qualitative examples showing the new capabilities of U-PaLM for single and multi-span infilling.
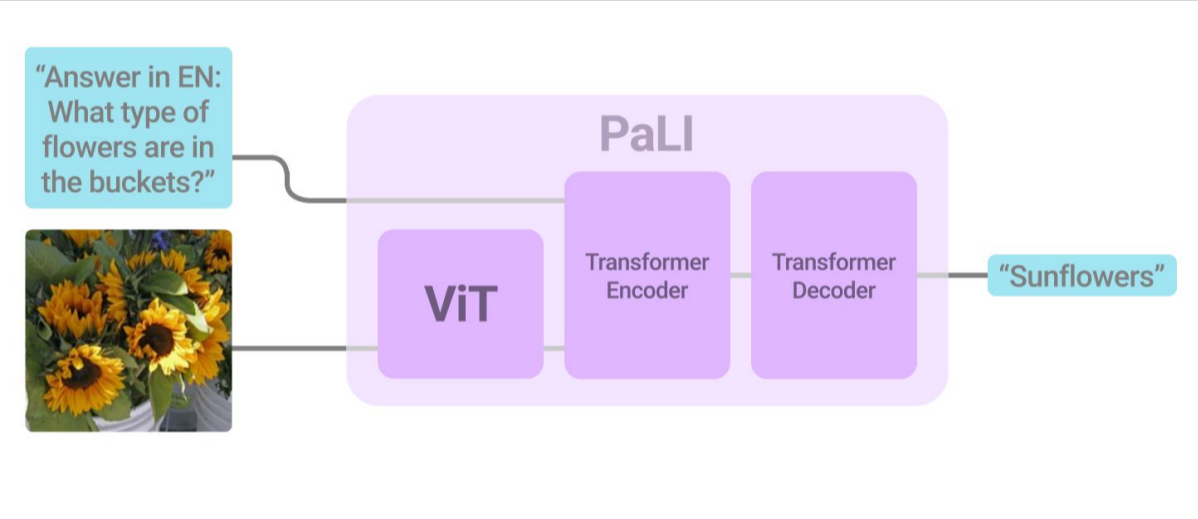
17. PaLI: A Jointly-Scaled Multilingual Language-Image Model
Authors: Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari, Gaurav Mishra, Linting Xue, Ashish Thapliyal, James Bradbury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu Karagol Ayan, Carlos Riquelme, Andreas Steiner, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, Radu Soricut
First appeared: 2022-09-14
Venue: International Conference on Learning Representations (ICLR), 2023 [notable-top-5%]
Full paper
► Abstract
Effective scaling and a flexible task interface enable large language models to excel at many tasks. We present PaLI (Pathways Language and Image model), a model that extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pre-trained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train a large, 4-billion parameter ViT (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
18. Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts
Authors: Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, Neil Houlsby
First appeared: 2022-06-06
Venue: Neural Information Processing Systems (NeurIPS), 2022
Full paper
► Abstract
Large sparsely-activated models have obtained excellent performance in multiple domains. However, such models are typically trained on a single modality at a time. We present the Language-Image MoE, LIMoE, a sparse mixture of experts model capable of multimodal learning. LIMoE accepts both images and text simultaneously, while being trained using a contrastive loss. MoEs are a natural fit for a multimodal backbone, since expert layers can learn an appropriate partitioning of modalities. However, new challenges arise; in particular, training stability and balanced expert utilization, for which we propose an entropy-based regularization scheme. Across multiple scales, we demonstrate remarkable performance improvement over dense models of equivalent computational cost. LIMoE-L/16 trained comparably to CLIP-L/14 achieves 78.6% zero-shot ImageNet accuracy (vs. 76.2%), and when further scaled to H/14 (with additional data) it achieves 84.1%, comparable to state-of-the-art methods which use larger custom per-modality backbones and pre-training schemes. We analyse the quantitative and qualitative behavior of LIMoE, and demonstrate phenomena such as differing treatment of the modalities and the organic emergence of modality-specific experts.
19. UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
Authors: Alexander Kolesnikov, André Susano Pinto, Lucas Beyer, Xiaohua Zhai, Jeremiah Harmsen, Neil Houlsby
First appeared: 2022-05-20
Venue: Neural Information Processing Systems (NeurIPS), 2022
Full paper
► Abstract
We introduce UViM, a unified approach capable of modeling a wide range of computer vision tasks. In contrast to previous models, UViM has the same functional form for all tasks; it requires no task-specific modifications which require extensive human expertise. The approach involves two components: (I) a base model (feed-forward) which is trained to directly predict raw vision outputs, guided by a learned discrete code and (II) a language model (autoregressive) that is trained to generate the guiding code. These components complement each other: the language model is well-suited to modeling structured interdependent data, while the base model is efficient at dealing with high-dimensional outputs. We demonstrate the effectiveness of UViM on three diverse and challenging vision tasks: panoptic segmentation, depth prediction and image colorization, where we achieve competitive and near state-of-the-art results. Our experimental results suggest that UViM is a promising candidate for a unified modeling approach in computer vision.
20. Robust and Efficient Medical Imaging with Self-Supervision
Authors: Shekoofeh Azizi, Laura Culp, Jan Freyberg, Basil Mustafa, Sebastien Baur, Simon Kornblith, Ting Chen, Patricia MacWilliams, S. Sara Mahdavi, Ellery Wulczyn, Boris Babenko, Megan Wilson, Aaron Loh, Po-Hsuan Cameron Chen, Yuan Liu, Pinal Bavishi, Scott Mayer McKinney, Jim Winkens, Abhijit Guha Roy, Zach Beaver, Fiona Ryan, Justin Krogue, Mozziyar Etemadi, Umesh Telang, Yun Liu, Lily Peng, Greg S. Corrado, Dale R. Webster, David Fleet, Geoffrey Hinton, Neil Houlsby, Alan Karthikesalingam, Mohammad Norouzi, Vivek Natarajan
First appeared: 2022-05-19
Venue: Nature Biomedical Engineering
Full paper
► Abstract
Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
21. Simple Open-Vocabulary Object Detection with Vision Transformers
Authors: Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, Neil Houlsby
First appeared: 2022-05-12
Venue: European Conference on Computer Vision (ECCV), 2020
Full paper
► Abstract
Combining simple architectures with large-scale pre-training has led to massive improvements in image classification. For object detection, pre-training and scaling approaches are less well established, especially in the long-tailed and open-vocabulary setting, where training data is relatively scarce. In this paper, we propose a strong recipe for transferring image-text models to open-vocabulary object detection. We use a standard Vision Transformer architecture with minimal modifications, contrastive image-text pre-training, and end-to-end detection fine-tuning. Our analysis of the scaling properties of this setup shows that increasing image-level pre-training and model size yield consistent improvements on the downstream detection task. We provide the adaptation strategies and regularizations needed to attain very strong performance on zero-shot text-conditioned and one-shot image-conditioned object detection. Code and models are available on GitHub.
22. Unifying Language Learning Paradigms
Authors: Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
First appeared: 2022-05-10
Venue: International Conference on Learning Representations (ICLR), 2023
Full paper
► Abstract
Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization. We release Flax-based T5X model checkpoints for the 20B model.
23. Do better ImageNet classifiers assess perceptual similarity better?
Authors: Manoj Kumar, Neil Houlsby, Nal Kalchbrenner, Ekin Cubuk
First appeared: 2022-03-09
Venue: Transactions on Machine Learning Research (TMLR)
Full paper
► Abstract
Perceptual distances between images, as measured in the space of pre-trained deep features, have outperformed prior low-level, pixel-based metrics on assessing image similarity. While the capabilities of older and less accurate models such as AlexNet and VGG to capture perceptual similarity are well known, modern and more accurate models are less studied. First, we observe a surprising inverse correlation between ImageNet accuracy and Perceptual Scores of modern networks such as ResNets, EfficientNets, and Vision Transformers: that is better classifiers achieve worse Perceptual Scores. Then, we perform a large-scale study and examine the ImageNet accuracy/Perceptual Score relationship on varying the depth, width, number of training steps, weight decay, label smoothing, and dropout. Higher accuracy improves Perceptual Score up to a certain point, but we uncover a Pareto frontier between accuracies and Perceptual Score in the mid-to-high accuracy regime. We explore this relationship further using distortion invariance, spatial frequency sensitivity, and alternative perceptual functions. Interestingly we discover shallow ResNets, trained for less than 5 epochs only on ImageNet, whose emergent Perceptual Score matches the prior best networks trained directly on supervised human perceptual judgements.
24. Learning to Merge Tokens in Vision Transformers
Authors: Cedric Renggli, André Susano Pinto, Neil Houlsby, Basil Mustafa, Joan Puigcerver, Carlos Riquelme
First appeared: 2022-02-24
Venue: arXiv, 2022
Full paper
► Abstract
Transformers are widely applied to solve natural language understanding and computer vision tasks. While scaling up these architectures leads to improved performance, it often comes at the expense of much higher computational costs. In order for large-scale models to remain practical in real-world systems, there is a need for reducing their computational overhead. In this work, we present the PatchMerger, a simple module that reduces the number of patches or tokens the network has to process by merging them between two consecutive intermediate layers. We show that the PatchMerger achieves a significant speedup across various model sizes while matching the original performance both upstream and downstream after fine-tuning.
25. Sparse MoEs meet Efficient Ensembles
Authors: James Urquhart Allingham, Florian Wenzel, Zelda E Mariet, Basil Mustafa, Joan Puigcerver, Neil Houlsby, Ghassen Jerfel, Vincent Fortuin, Balaji Lakshminarayanan, Jasper Snoek, Dustin Tran, Carlos Riquelme Ruiz, Rodolphe Jenatton
First appeared: 2021-10-07
Venue: Transactions on Machine Learning Research (TMLR)
Full paper
► Abstract
Machine learning models based on the aggregated outputs of submodels, either at the activation or prediction levels, often exhibit strong performance compared to individual models. We study the interplay of two popular classes of such models: ensembles of neural networks and sparse mixture of experts (sparse MoEs). First, we show that the two approaches have complementary features whose combination is beneficial. This includes a comprehensive evaluation of sparse MoEs in uncertainty related benchmarks. Then, we present Efficient Ensemble of Experts (E^3), a scalable and simple ensemble of sparse MoEs that takes the best of both classes of models, while using up to 45% fewer FLOPs than a deep ensemble. Extensive experiments demonstrate the accuracy, log-likelihood, few-shot learning, robustness, and uncertainty improvements of E^3 over several challenging vision Transformer-based baselines. E^3 not only preserves its efficiency while scaling to models with up to 2.7B parameters, but also provides better predictive performance and uncertainty estimates for larger models.
26. The Benchmark Lottery
Authors: Mostafa Dehghani, Yi Tay, Alexey A. Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, Oriol Vinyals
First appeared: 2021-07-14
Venue: arXiv, 2021
Full paper
► Abstract
The world of empirical machine learning (ML) strongly relies on benchmarks in order to determine the relative effectiveness of different algorithms and methods. This paper proposes the notion of "a benchmark lottery" that describes the overall fragility of the ML benchmarking process. The benchmark lottery postulates that many factors, other than fundamental algorithmic superiority, may lead to a method being perceived as superior. On multiple benchmark setups that are prevalent in the ML community, we show that the relative performance of algorithms may be altered significantly simply by choosing different benchmark tasks, highlighting the fragility of the current paradigms and potential fallacious interpretation derived from benchmarking ML methods. Given that every benchmark makes a statement about what it perceives to be important, we argue that this might lead to biased progress in the community. We discuss the implications of the observed phenomena and provide recommendations on mitigating them using multiple machine learning domains and communities as use cases, including natural language processing, computer vision, information retrieval, recommender systems, and reinforcement learning.
27. Revisiting the Calibration of Modern Neural Networks
Authors: Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, Mario Lucic
First appeared: 2021-06-15
Venue: Neural Information Processing Systems (NeurIPS), 2021
Full paper
► Abstract
Accurate estimation of predictive uncertainty (model calibration) is essential for the safe application of neural networks. Many instances of miscalibration in modern neural networks have been reported, suggesting a trend that newer, more accurate models produce poorly calibrated predictions. Here, we revisit this question for recent state-of-the-art image classification models. We systematically relate model calibration and accuracy, and find that the most recent models, notably those not using convolutions, are among the best calibrated. Trends observed in prior model generations, such as decay of calibration with distribution shift or model size, are less pronounced in recent architectures. We also show that model size and amount of pretraining do not fully explain these differences, suggesting that architecture is a major determinant of calibration properties.
28. Scaling Vision with Sparse Mixture of Experts
Authors: Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, Neil Houlsby
First appeared: 2021-06-10
Venue: Neural Information Processing Systems (NeurIPS), 2021
Full paper
► Abstract
Sparsely-gated Mixture of Experts networks (MoEs) have demonstrated excellent scalability in Natural Language Processing. In Computer Vision, however, almost all performant networks are "dense", that is, every input is processed by every parameter. We present a Vision MoE (V-MoE), a sparse version of the Vision Transformer, that is scalable and competitive with the largest dense networks. When applied to image recognition, V-MoE matches the performance of state-of-the-art networks, while requiring as little as half of the compute at inference time. Further, we propose an extension to the routing algorithm that can prioritize subsets of each input across the entire batch, leading to adaptive per-image compute. This allows V-MoE to trade-off performance and compute smoothly at test-time. Finally, we demonstrate the potential of V-MoE to scale vision models, and train a 15B parameter model that attains 90.35% on ImageNet.
29. Scaling Vision Transformers
Authors: Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, Lucas Beyer
First appeared: 2021-06-08
Venue: Computer Vision and Pattern Recognition (CVPR), 2022
Full paper
► Abstract
Attention-based neural networks such as the Vision Transformer (ViT) have recently attained state-of-the-art results on many computer vision benchmarks. Scale is a primary ingredient in attaining excellent results, therefore, understanding a model's scaling properties is a key to designing future generations effectively. While the laws for scaling Transformer language models have been studied, it is unknown how Vision Transformers scale. To address this, we scale ViT models and data, both up and down, and characterize the relationships between error rate, data, and compute. Along the way, we refine the architecture and training of ViT, reducing memory consumption and increasing accuracy of the resulting models. As a result, we successfully train a ViT model with two billion parameters, which attains a new state-of-the-art on ImageNet of 90.45% top-1 accuracy. The model also performs well for few-shot transfer, for example, reaching 84.86% top-1 accuracy on ImageNet with only 10 examples per class.
30. SI-Score: An image dataset for fine-grained analysis of robustness to object location, rotation and size
Authors: Jessica Yung, Rob Romijnders, Alexander Kolesnikov, Lucas Beyer, Josip Djolonga, Neil Houlsby, Sylvain Gelly, Mario Lucic, Xiaohua Zhai
First appeared: 2021-05-09
Venue: International Conference on Learning Represenations RobustML Workshop, 2021
Full paper
► Abstract
Before deploying machine learning models it is critical to assess their robustness. In the context of deep neural networks for image understanding, changing the object location, rotation and size may affect the predictions in non-trivial ways. In this work we perform a fine-grained analysis of robustness with respect to these factors of variation using SI-Score, a synthetic dataset. In particular, we investigate ResNets, Vision Transformers and CLIP, and identify interesting qualitative differences between these.
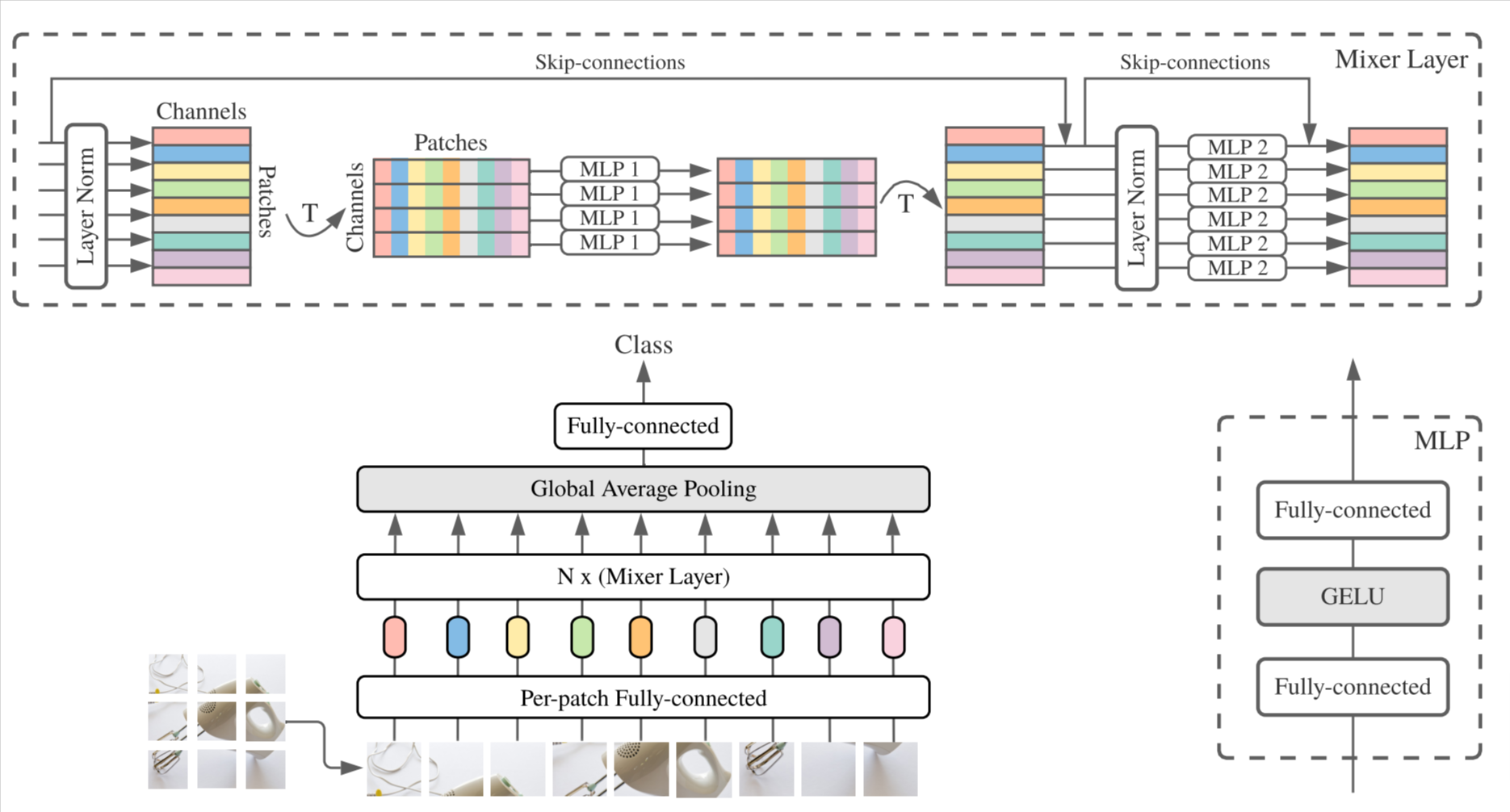
31. MLP-Mixer: An all-MLP Architecture for Vision
Authors: Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy
First appeared: 2021-05-04
Venue: Neural Information Processing Systems (NeurIPS)
Full paper
► Abstract
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
32. Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark
Authors: Vincent Dumoulin, Neil Houlsby, Utku Evci, Xiaohua Zhai, Ross Goroshin, Sylvain Gelly, Hugo Larochelle
First appeared: 2021-04-06
Venue: Neural Information Processing Systems Datasets and Benchmarks Track, 2021
Full paper
► Abstract
Meta and transfer learning are two successful families of approaches to few-shot learning. Despite highly related goals, state-of-the-art advances in each family are measured largely in isolation of each other. As a result of diverging evaluation norms, a direct or thorough comparison of different approaches is challenging. To bridge this gap, we perform a cross-family study of the best transfer and meta learners on both a large-scale meta-learning benchmark (Meta-Dataset, MD), and a transfer learning benchmark (Visual Task Adaptation Benchmark, VTAB). We find that, on average, large-scale transfer methods (Big Transfer, BiT) outperform competing approaches on MD, even when trained only on ImageNet. In contrast, meta-learning approaches struggle to compete on VTAB when trained and validated on MD. However, BiT is not without limitations, and pushing for scale does not improve performance on highly out-of-distribution MD tasks. In performing this study, we reveal a number of discrepancies in evaluation norms and study some of these in light of the performance gap. We hope that this work facilitates sharing of insights from each community, and accelerates progress on few-shot learning.
33. Supervised Transfer Learning at Scale for Medical Imaging
Authors: Basil Mustafa, Aaron Loh, Jan Freyberg, Patricia MacWilliams, Megan Wilson, Scott Mayer McKinney, Marcin Sieniek, Jim Winkens, Yuan Liu, Peggy Bui, Shruthi Prabhakara, Umesh Telang, Alan Karthikesalingam, Neil Houlsby, Vivek Natarajan
First appeared: 2021-01-14
Venue: arXiv, 2021
Full paper
► Abstract
Transfer learning is a standard technique to improve performance on tasks with limited data. However, for medical imaging, the value of transfer learning is less clear. This is likely due to the large domain mismatch between the usual natural-image pre-training (e.g. ImageNet) and medical images. However, recent advances in transfer learning have shown substantial improvements from scale. We investigate whether modern methods can change the fortune of transfer learning for medical imaging. For this, we study the class of large-scale pre-trained networks presented by Kolesnikov et al. on three diverse imaging tasks: chest radiography, mammography, and dermatology. We study both transfer performance and critical properties for the deployment in the medical domain, including: out-of-distribution generalization, data-efficiency, sub-group fairness, and uncertainty estimation. Interestingly, we find that for some of these properties transfer from natural to medical images is indeed extremely effective, but only when performed at sufficient scale.
34. Underspecification Presents Challenges for Credibility in Modern Machine Learning
Authors: Alexander D'Amour, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen, Jonathan Deaton, Jacob Eisenstein, Matthew D. Hoffman, Farhad Hormozdiari, Neil Houlsby, Shaobo Hou, Ghassen Jerfel, Alan Karthikesalingam, Mario Lucic, Yian Ma, Cory McLean, Diana Mincu, Akinori Mitani, Andrea Montanari, Zachary Nado, Vivek Natarajan, Christopher Nielson, Thomas F. Osborne, Rajiv Raman, Kim Ramasamy, Rory Sayres, Jessica Schrouff, Martin Seneviratne, Shannon Sequeira, Harini Suresh, Victor Veitch, Max Vladymyrov, Xuezhi Wang, Kellie Webster, Steve Yadlowsky, Taedong Yun, Xiaohua Zhai, D. Sculley
First appeared: 2020-11-06
Venue: Journal of Machine Learning Research (JMLR)
Full paper
► Abstract
ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
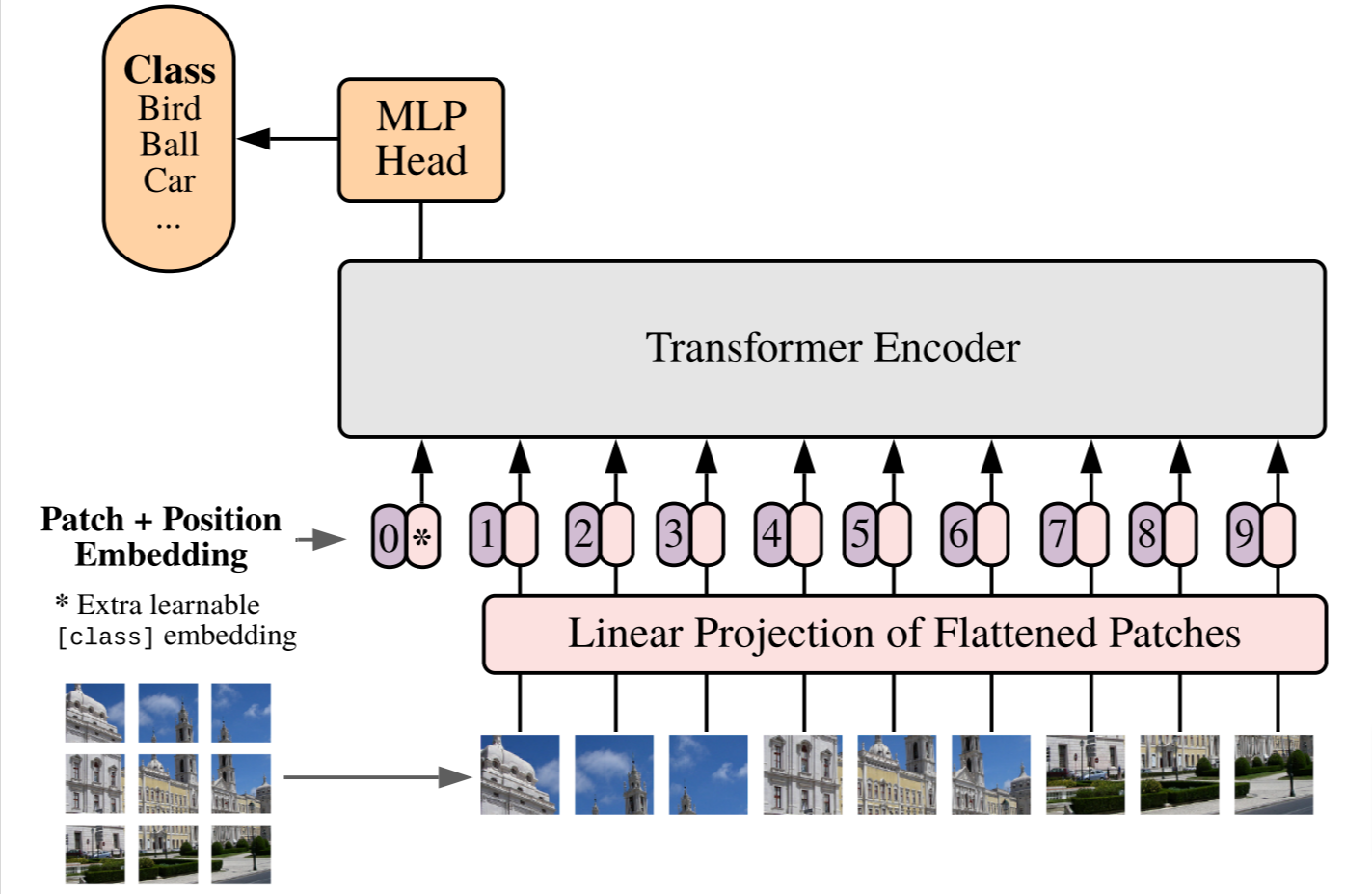
35. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Authors: Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
First appeared: 2020-10-22
Venue: International Conference on Learning Representations (ICLR), 2021
Full paper
► Abstract
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
36. Deep Ensembles for Low-Data Transfer Learning
Authors: Basil Mustafa, Carlos Riquelme, Joan Puigcerver, André Susano Pinto, Daniel Keysers, Neil Houlsby
First appeared: 2020-10-14
Venue: arXiv, 2020
Full paper
► Abstract
In the low-data regime, it is difficult to train good supervised models from scratch. Instead practitioners turn to pre-trained models, leveraging transfer learning. Ensembling is an empirically and theoretically appealing way to construct powerful predictive models, but the predominant approach of training multiple deep networks with different random initialisations collides with the need for transfer via pre-trained weights. In this work, we study different ways of creating ensembles from pre-trained models. We show that the nature of pre-training itself is a performant source of diversity, and propose a practical algorithm that efficiently identifies a subset of pre-trained models for any downstream dataset. The approach is simple: Use nearest-neighbour accuracy to rank pre-trained models, fine-tune the best ones with a small hyperparameter sweep, and greedily construct an ensemble to minimise validation cross-entropy. When evaluated together with strong baselines on 19 different downstream tasks (the Visual Task Adaptation Benchmark), this achieves state-of-the-art performance at a much lower inference budget, even when selecting from over 2,000 pre-trained models. We also assess our ensembles on ImageNet variants and show improved robustness to distribution shift.
37. Representation Learning From Videos In-the-Wild: An Object-Centric Approach
Authors: Rob Romijnders, Aravindh Mahendran, Michael Tschannen, Josip Djolonga, Marvin Ritter, Neil Houlsby, Mario Lucic
First appeared: 2020-10-06
Venue: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021
Full paper
► Abstract
We propose a method to learn image representations from uncurated videos. We combine a supervised loss from off-the-shelf object detectors and self-supervised losses which naturally arise from the video-shot-frame-object hierarchy present in each video. We report competitive results on 19 transfer learning tasks of the Visual Task Adaptation Benchmark (VTAB), and on 8 out-of-distribution-generalization tasks, and discuss the benefits and shortcomings of the proposed approach. In particular, it improves over the baseline on all 18/19 few-shot learning tasks and 8/8 out-of-distribution generalization tasks. Finally, we perform several ablation studies and analyze the impact of the pretrained object detector on the performance across this suite of tasks.
38. Training General Representations for Remote Sensing Using In-Domain Knowledge
Authors: Maxim Neumann, Andre Susano Pinto, Xiaohua Zhai, Neil Houlsby
First appeared: 2020-09-30
Venue: IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 2020
Full paper
► Abstract
Automatically finding good and general remote sensing representations allows to perform transfer learning on a wide range of applications - improving the accuracy and reducing the required number of training samples. This paper investigates development of generic remote sensing representations, and explores which characteristics are important for a dataset to be a good source for representation learning. For this analysis, five diverse remote sensing datasets are selected and used for both, disjoint upstream representation learning and downstream model training and evaluation. A common evaluation protocol is used to establish baselines for these datasets that achieve state-of-the-art performance. As the results indicate, especially with a low number of available training samples a significant performance enhancement can be observed when including additionally in-domain data in comparison to training models from scratch or fine-tuning only on ImageNet (up to 11% and 40%, respectively, at 100 training samples). All datasets and pretrained representation models are published online.
39. Scalable Transfer Learning with Expert Models
Authors: Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Cedric Renggli, André Susano Pinto, Sylvain Gelly, Daniel Keysers, Neil Houlsby
First appeared: 2020-09-28
Venue: International Conference on Learning Representations (ICLR), 2021
Full paper
► Abstract
Transfer of pre-trained representations can improve sample efficiency and reduce computational requirements for new tasks. However, representations used for transfer are usually generic, and are not tailored to a particular distribution of downstream tasks. We explore the use of expert representations for transfer with a simple, yet effective, strategy. We train a diverse set of experts by exploiting existing label structures, and use cheap-to-compute performance proxies to select the relevant expert for each target task. This strategy scales the process of transferring to new tasks, since it does not revisit the pre-training data during transfer. Accordingly, it requires little extra compute per target task, and results in a speed-up of 2-3 orders of magnitude compared to competing approaches. Further, we provide an adapter-based architecture able to compress many experts into a single model. We evaluate our approach on two different data sources and demonstrate that it outperforms baselines on over 20 diverse vision tasks in both cases.
40. On Robustness and Transferability of Convolutional Neural Networks
Authors: Josip Djolonga, Jessica Yung, Michael Tschannen, Rob Romijnders, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Matthias Minderer, Alexander D'Amour, Dan Moldovan, Sylvain Gelly, Neil Houlsby, Xiaohua Zhai, Mario Lucic
First appeared: 2020-07-16
Venue: Computer Vision and Pattern Recognition (CVPR), 2021
Full paper
► Abstract
Modern deep convolutional networks (CNNs) are often criticized for not generalizing under distributional shifts. However, several recent breakthroughs in transfer learning suggest that these networks can cope with severe distribution shifts and successfully adapt to new tasks from a few training examples. In this work we study the interplay between out-of-distribution and transfer performance of modern image classification CNNs for the first time and investigate the impact of the pre-training data size, the model scale, and the data preprocessing pipeline. We find that increasing both the training set and model sizes significantly improve the distributional shift robustness. Furthermore, we show that, perhaps surprisingly, simple changes in the preprocessing such as modifying the image resolution can significantly mitigate robustness issues in some cases. Finally, we outline the shortcomings of existing robustness evaluation datasets and introduce a synthetic dataset SI-Score we use for a systematic analysis across factors of variation common in visual data such as object scale and position.
41. Automatic Shortcut Removal for Self-Supervised Representation Learning
Authors: Matthias Minderer, Olivier Bachem, Neil Houlsby, Michael Tschannen
First appeared: 2020-02-20
Venue: International Conference on Machine Learning (ICML), 2020
Full paper
► Abstract
In self-supervised visual representation learning, a feature extractor is trained on a "pretext task" for which labels can be generated cheaply, without human annotation. A central challenge in this approach is that the feature extractor quickly learns to exploit low-level visual features such as color aberrations or watermarks and then fails to learn useful semantic representations. Much work has gone into identifying such "shortcut" features and hand-designing schemes to reduce their effect. Here, we propose a general framework for mitigating the effect shortcut features. Our key assumption is that those features which are the first to be exploited for solving the pretext task may also be the most vulnerable to an adversary trained to make the task harder. We show that this assumption holds across common pretext tasks and datasets by training a "lens" network to make small image changes that maximally reduce performance in the pretext task. Representations learned with the modified images outperform those learned without in all tested cases. Additionally, the modifications made by the lens reveal how the choice of pretext task and dataset affects the features learned by self-supervision.
42. Big Transfer (BiT): General Visual Representation Learning
Authors: Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby
First appeared: 2019-12-24
Venue: European Conference on Computer Vision (ECCV), 2020
Full paper
► Abstract
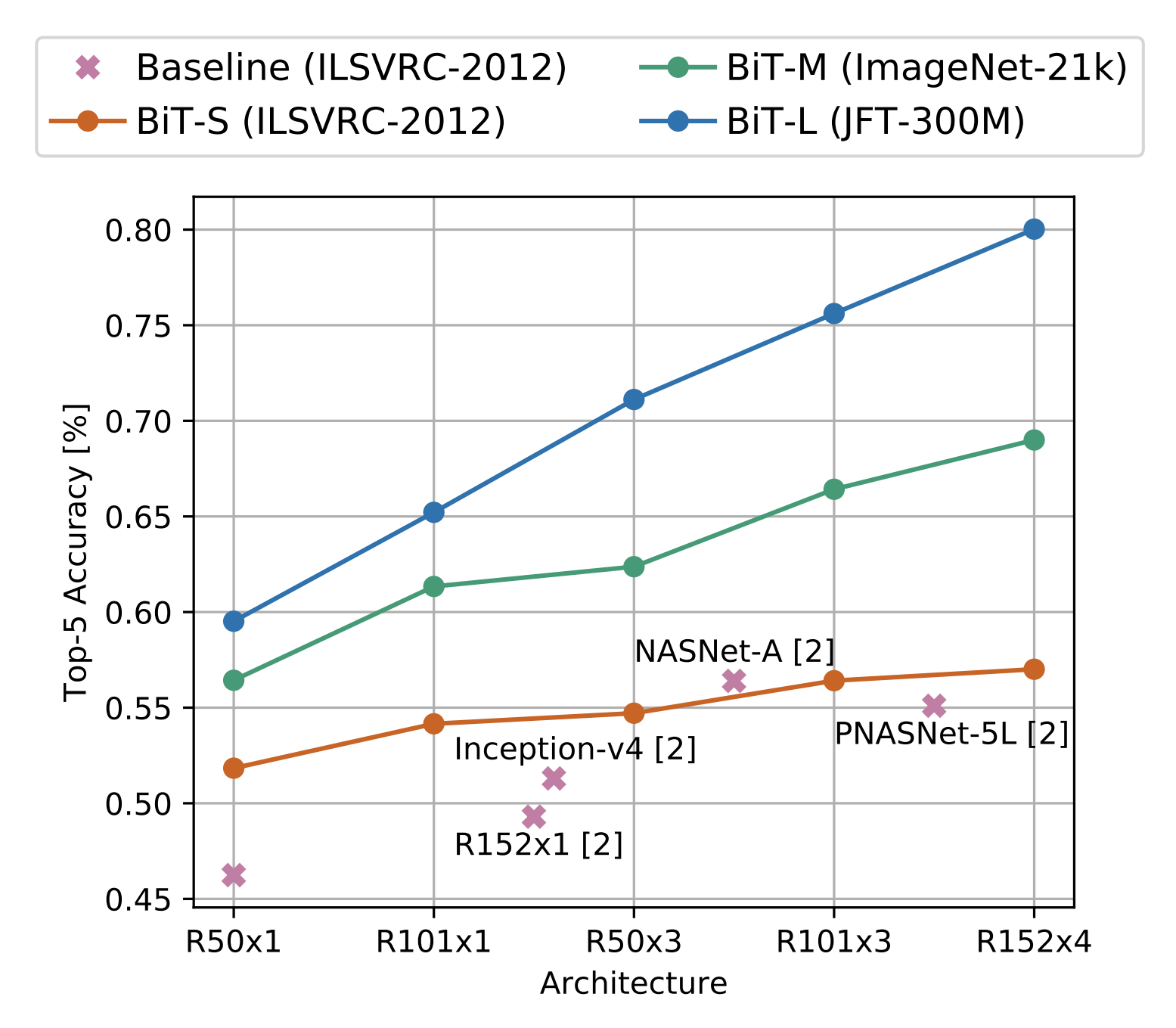
Transfer of pre-trained representations improves sample efficiency and simplifies hyperparameter tuning when training deep neural networks for vision. We revisit the paradigm of pre-training on large supervised datasets and fine-tuning the model on a target task. We scale up pre-training, and propose a simple recipe that we call Big Transfer (BiT). By combining a few carefully selected components, and transferring using a simple heuristic, we achieve strong performance on over 20 datasets. BiT performs well across a surprisingly wide range of data regimes -- from 1 example per class to 1M total examples. BiT achieves 87.5% top-1 accuracy on ILSVRC-2012, 99.4% on CIFAR-10, and 76.3% on the 19 task Visual Task Adaptation Benchmark (VTAB). On small datasets, BiT attains 76.8% on ILSVRC-2012 with 10 examples per class, and 97.0% on CIFAR-10 with 10 examples per class. We conduct detailed analysis of the main components that lead to high transfer performance.
43. Self-Supervised Learning of Video-Induced Visual Invariances
Authors: Michael Tschannen, Josip Djolonga, Marvin Ritter, Aravindh Mahendran, Xiaohua Zhai, Neil Houlsby, Sylvain Gelly, Mario Lucic
First appeared: 2019-12-05
Venue: Computer Vision and Pattern Recognition (CVPR), 2020
Full paper
► Abstract
We propose a general framework for self-supervised learning of transferable visual representations based on Video-Induced Visual Invariances (VIVI). We consider the implicit hierarchy present in the videos and make use of (i) frame-level invariances (e.g. stability to color and contrast perturbations), (ii) shot/clip-level invariances (e.g. robustness to changes in object orientation and lighting conditions), and (iii) video-level invariances (semantic relationships of scenes across shots/clips), to define a holistic self-supervised loss. Training models using different variants of the proposed framework on videos from the YouTube-8M (YT8M) data set, we obtain state-of-the-art self-supervised transfer learning results on the 19 diverse downstream tasks of the Visual Task Adaptation Benchmark (VTAB), using only 1000 labels per task. We then show how to co-train our models jointly with labeled images, outperforming an ImageNet-pretrained ResNet-50 by 0.8 points with 10x fewer labeled images, as well as the previous best supervised model by 3.7 points using the full ImageNet data set.
44. A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark
Authors: Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, Lucas Beyer, Olivier Bachem, Michael Tschannen, Marcin Michalski, Olivier Bousquet, Sylvain Gelly, Neil Houlsby
First appeared: 2019-10-01
Venue: arXiv, 2019
Full paper
► Abstract
Representation learning promises to unlock deep learning for the long tail of vision tasks without expensive labelled datasets. Yet, the absence of a unified evaluation for general visual representations hinders progress. Popular protocols are often too constrained (linear classification), limited in diversity (ImageNet, CIFAR, Pascal-VOC), or only weakly related to representation quality (ELBO, reconstruction error). We present the Visual Task Adaptation Benchmark (VTAB), which defines good representations as those that adapt to diverse, unseen tasks with few examples. With VTAB, we conduct a large-scale study of many popular publicly-available representation learning algorithms. We carefully control confounders such as architecture and tuning budget. We address questions like: How effective are ImageNet representations beyond standard natural datasets? How do representations trained via generative and discriminative models compare? To what extent can self-supervision replace labels? And, how close are we to general visual representations?
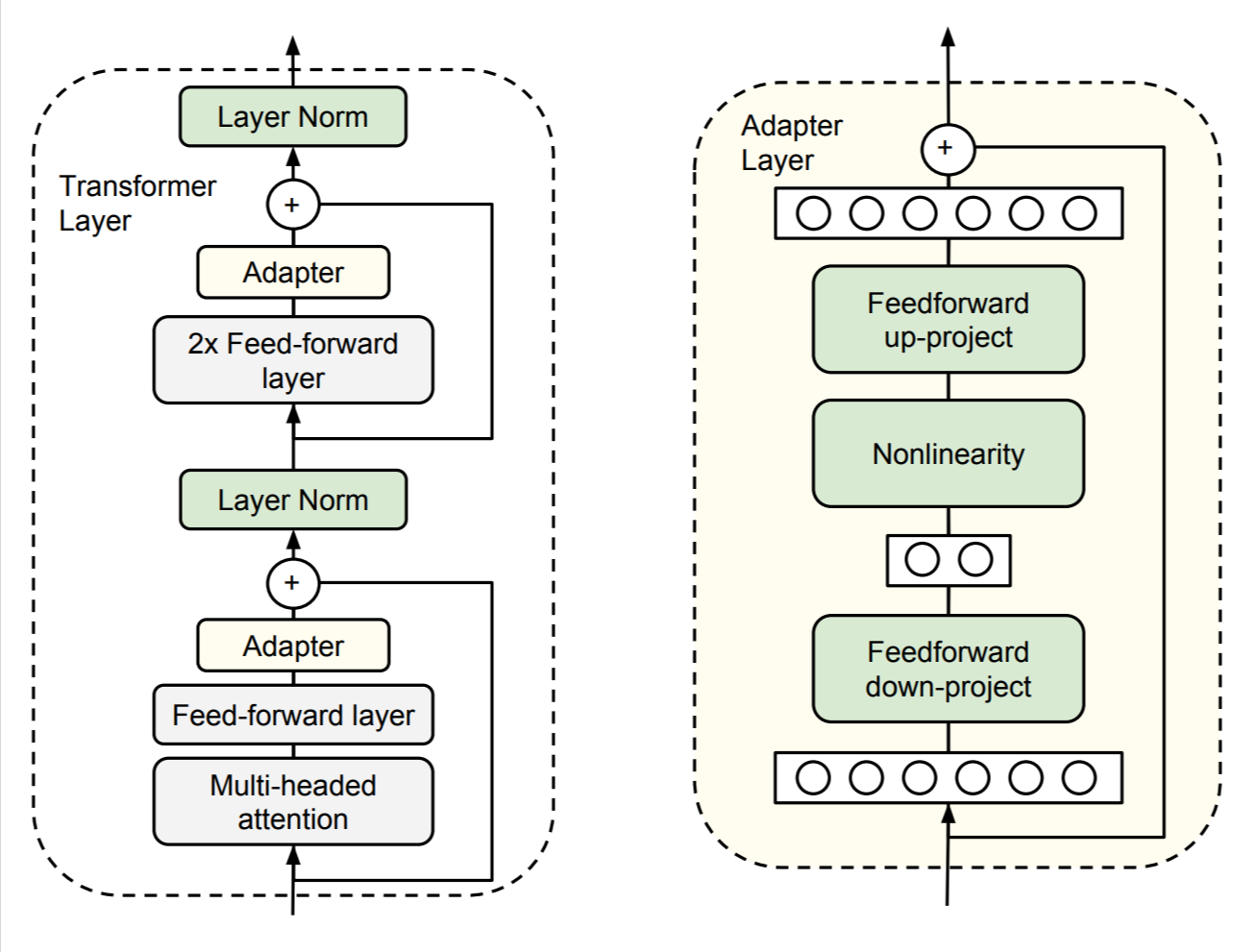
45. Parameter-Efficient Transfer Learning for NLP
Authors: Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, Sylvain Gelly
First appeared: 2019-02-02
Venue: International Conference on Machine Learning (ICML), 2019
Full paper
► Abstract
Fine-tuning large pretrained models is an effective transfer mechanism in NLP. However, in the presence of many downstream tasks, fine-tuning is parameter inefficient: an entire new model is required for every task. As an alternative, we propose transfer with adapter modules. Adapter modules yield a compact and extensible model; they add only a few trainable parameters per task, and new tasks can be added without revisiting previous ones. The parameters of the original network remain fixed, yielding a high degree of parameter sharing. To demonstrate adapter's effectiveness, we transfer the recently proposed BERT Transformer model to
26 diverse text classification tasks, including the GLUE benchmark. Adapters attain near state-of-the-art performance, whilst adding only a few parameters per task. On GLUE, we attain within 0.8% of the performance of full fine-tuning, adding only 3.6% parameters per task. By contrast, fine-tuning trains 100% of the parameters per task.
46. Neural Architecture Search Over a Graph Search Space
Authors: Stanisław Jastrzębski, Quentin de Laroussilhe, Mingxing Tan, Xiao Ma, Neil Houlsby, Andrea Gesmundo
First appeared: 2018-12-27
Venue: arXiv, 2018
Full paper
► Abstract
Neural Architecture Search (NAS) enabled the discovery of state-of-the-art architectures in many domains. However, the success of NAS depends on the definition of the search space. Current search spaces are defined as a static sequence of decisions and a set of available actions for each decision. Each possible sequence of actions defines an architecture. We propose a more expressive class of search space: directed graphs. In our formalism, each decision is a vertex and each action is an edge. This allows us to model iterative and branching architecture design decisions. We demonstrate in simulation, and on image classification experiments, basic iterative and branching search structures, and show that the graph representation improves sample efficiency.
47. Self-Supervised GANs via Auxiliary Rotation Loss
Authors: Ting Chen, Xiaohua Zhai, Marvin Ritter, Mario Lucic, Neil Houlsby
First appeared: 2018-11-27
Venue: Computer Vision and Pattern Recognition (CVPR), 2019
Full paper
► Abstract
Conditional GANs are at the forefront of natural image
synthesis. The main drawback of such models is the necessity for labeled data. In this work we exploit two popular
unsupervised learning techniques, adversarial training and
self-supervision, and take a step towards bridging the gap
between conditional and unconditional GANs. In particular,
we allow the networks to collaborate on the task of representation learning, while being adversarial with respect to
the classic GAN game. The role of self-supervision is to
encourage the discriminator to learn meaningful feature representations which are not forgotten during training. We test
empirically both the quality of the learned image representations, and the quality of the synthesized images. Under
the same conditions, the self-supervised GAN attains a similar performance to state-of-the-art conditional counterparts.
Finally, we show that this approach to fully unsupervised
learning can be scaled to attain an FID of 23.4 on unconditional ImageNet generation.
48. On Self Modulation for Generative Adversarial Networks
Authors: Ting Chen, Mario Lucic, Neil Houlsby, Sylvain Gelly
First appeared: 2018-10-02
Venue: International Conference on Learning Representations (ICLR), 2019
Full paper
► Abstract
Training Generative Adversarial Networks (GANs) is notoriously challenging. We propose and study an architectural modification, self-modulation, which improves GAN performance across different data sets, architectures, losses, regularizers, and hyperparameter settings. Intuitively, self-modulation allows the intermediate feature maps of a generator to change as a function of the input noise vector. While reminiscent of other conditioning techniques, it requires no labeled data. In a large-scale empirical study we observe a relative decrease of 5%-35% in FID. Furthermore, all else being equal, adding this modification to the generator leads to improved performance in 124/144 (86%) of the studied settings. Self-modulation is a simple architectural change that requires no additional parameter tuning, which suggests that it can be applied readily to any GAN.
49. Transfer Learning with Neural AutoML
Authors: Catherine Wong, Neil Houlsby, Yifeng Lu, Andrea Gesmundo
First appeared: 2018-03-07
Venue: Neural Information Processing Systems (NeurIPS), 2018
Full paper
► Abstract
We reduce the computational cost of Neural AutoML with transfer learning. AutoML relieves human effort by automating the design of ML algorithms. Neural AutoML has become popular for the design of deep learning architectures, however, this method has a high computation cost. To address this we propose Transfer Neural AutoML that uses knowledge from prior tasks to speed up network design. We extend RL-based architecture search methods to support parallel training on multiple tasks and then transfer the search strategy to new tasks. On language and image classification data, Transfer Neural AutoML reduces convergence time over single-task training by over an order of magnitude on many tasks.
50. Ask the Right Questions: Active Question Reformulation with Reinforcement Learning
Authors: Christian Buck, Jannis Bulian, Massimiliano Ciaramita, Wojciech Gajewski, Andrea Gesmundo, Neil Houlsby, Wei Wang
First appeared: 2017-05-22
Venue: International Conference on Learning Representations (ICLR), 2018 [Oral]
Full paper
► Abstract
We frame Question Answering (QA) as a Reinforcement Learning task, an approach that we call Active Question Answering.
We propose an agent that sits between the user and a black box QA system and learns to reformulate questions to elicit the best possible answers. The agent probes the system with, potentially many, natural language reformulations of an initial question and aggregates the returned evidence to yield the best answer.
The reformulation system is trained end-to-end to maximize answer quality using policy gradient. We evaluate on SearchQA, a dataset of complex questions extracted from Jeopardy!. The agent outperforms a state-of-the-art base model, playing the role of the environment, and other benchmarks.
We also analyze the language that the agent has learned while interacting with the question answering system. We find that successful question reformulations look quite different from natural language paraphrases. The agent is able to discover non-trivial reformulation strategies that resemble classic information retrieval techniques such as term re-weighting (tf-idf) and stemming.
51. A Filtering Approach to Stochastic Variational Inference
Authors: Neil Houlsby, David Blei
First appeared: 2014-12-08
Venue: Neural Information Processing Systems (NeurIPS), 2014
Full paper
► Abstract
Stochastic variational inference (SVI) uses stochastic optimization to scale up Bayesian computation to massive data. We present an alternative perspective on SVI as approximate parallel coordinate ascent. SVI trades-off bias and variance to step close to the unknown true coordinate optimum given by batch variational Bayes (VB). We define a model to automate this process. The model infers the location of the next VB optimum from a sequence of noisy realizations. As a consequence of this construction, we update the variational parameters using Bayes rule, rather than a hand-crafted optimization schedule. When our model is a Kalman filter this procedure can recover the original SVI algorithm and SVI with adaptive steps. We may also encode additional assumptions in the model, such as heavy-tailed noise. By doing so, our algorithm outperforms the original SVI schedule and a state-of-the-art adaptive SVI algorithm in two diverse domains.
52. Efficient Bayesian Active Learning and Matrix Modelling
Authors: Neil Houlsby
First appeared: 2014-11-11
Venue: Doctor of Philosophy (PhD), University of Cambridge
Full paper
► Abstract
With the advent of the Internet and growth of storage capabilities, large collections of unlabelled data are now available. However, collecting supervised labels can be costly. Active learning addresses this by selecting, sequentially, only the most useful data in light of the information collected so far. The online nature of such algorithms often necessitates efficient computations. Thus, we present a framework for information theoretic Bayesian active learning, named Bayesian Active Learning by Disagreement, that permits efficient and accurate computations of data utility. Using this framework we develop new techniques for active Gaussian process modelling and adaptive quantum tomography. The latter has been shown, in both simulation and laboratory experiments, to yield faster learning rates than any non-adaptive design. Numerous datasets can be represented as matrices. Bayesian models of matrices are becoming increasingly popular because they can handle noisy or missing elements, and are extensible to different data-types. However, efficient inference is crucial to allow these flexible probabilistic models to scale to large real-world datasets. Binary matrices are a ubiquitous datatype, so we present a stochastic inference algorithm for fast learning in this domain. Preference judgements are a common, implicit source of binary data. We present a hybrid matrix factorization/Gaussian process model for collaborative learning from multiple users' preferences. This model exploits both the structure of the matrix and can incorporate additional covariate information to make accurate predictions. We then combine matrix modelling with active learning and propose a new algorithm for cold-start learning with ordinal data, such as ratings. This algorithm couples Bayesian Active Learning by Disagreement with a heteroscedastic model to handle varying levels of noise. This ordinal matrix model is also used to analyze psychometric questionnaires; we analyze classical assumptions made in psychometrics and show that active learning methods can reduce questionnaire lengths substantially.
53. Cold-start Active Learning with Robust Ordinal Matrix Factorization
Authors: Cold-start Active Learning with Robust Ordinal Matrix Factorization
First appeared: 2014-06-21
Venue: International Conference on Machine Learning (ICML), 2014
Full paper
► Abstract
We present a new matrix factorization model for rating data and a corresponding active learning strategy to address the cold-start problem. Cold-start is one of the most challenging tasks for recommender systems: what to recommend with new users or items for which one has little or no data. An approach is to use active learning to collect the most useful initial ratings. However, the performance of active learning depends strongly upon having accurate estimates of i) the uncertainty in model parameters and ii) the intrinsic noisiness of the data. To achieve these estimates we propose a heteroskedastic Bayesian model for ordinal matrix factorization. We also present a computationally efficient framework for Bayesian active learning with this type of complex probabilistic model. This algorithm successfully distinguishes between informative and noisy data points. Our model yields state-of-the-art predictive performance and, coupled with our active learning strategy, enables us to gain useful information in the cold-start setting from the very first active sample.
54. Probabilistic Matrix Factorization with Non-random Missing Data
Authors: José Miguel Hernández-Lobato, Neil Houlsby, Zoubin Ghahramani
First appeared: 2014-06-21
Venue: International Conference on Machine Learning (ICML)
Full paper
► Abstract
We propose a probabilistic matrix factorization model for collaborative filtering that learns from data that is missing not at random (MNAR). Matrix factorization models exhibit state-of-the-art predictive performance in collaborative filtering. However, these models usually assume that the data is missing at random (MAR), and this is rarely the case. For example, the data is not MAR if users rate items they like more than ones they dislike. When the MAR assumption is incorrect, inferences are biased and predictive performance can suffer. Therefore, we model both the generative process for the data and the missing data mechanism. By learning these two models jointly we obtain improved performance over state-of-the-art methods when predicting the ratings and when modeling the data observation process. We present the first viable MF model for MNAR data. Our results are promising and we expect that further research on NMAR models will yield large gains in collaborative filtering.
55. Stochastic Inference for Scalable Probabilistic Modeling of Binary Matrices
Authors: José Miguel Hernández-Lobato, Neil Houlsby, Zoubin Ghahramani
First appeared: 2014-06-21
Venue: International Conference on Machine Learning (ICML), 2021
Full paper
► Abstract
Fully observed large binary matrices appear in a wide variety of contexts. To model them, probabilistic matrix factorization (PMF) methods are an attractive solution. However, current batch algorithms for PMF can be inefficient because they need to analyze the entire data matrix before producing any parameter updates. We derive an efficient stochastic inference algorithm for PMF models of fully observed binary matrices. Our method exhibits faster convergence rates than more expensive batch approaches and has better predictive performance than scalable alternatives. The proposed method includes new data subsampling strategies which produce large gains over standard uniform subsampling. We also address the task of automatically selecting the size of the minibatches of data used by our method. For this, we derive an algorithm that adjusts this hyper-parameter online.
56. Statistical Fitting of Undrained Strength Data
Authors: Neil Houlsby, Guy Houlsby
First appeared: 2013-11-01
Venue: Géotechnique
Full paper
► Abstract
An approach is described, based on Bayesian statistical methods, that allows the fitting of a design profile to a set of measurements of undrained strengths. In particular allowance is made for the automatic determination of not only the positions of boundaries between geological units, but also the selection of the number of units to model the data in an appropriate way.
57. Cognitive Tomography Reveals Complex Task-Independent Mental Representations
Authors: Neil Houlsby, Ferenc Huszár, Mohammad Ghassemi, Gergő Orbán, Daniel Wolpert, Máté Lengyel
First appeared: 2013-10-24
Venue: Current Biology
Full paper
► Abstract
Humans develop rich mental representations that guide their behavior in a variety of everyday tasks. However, it is unknown whether these representations, often formalized as priors in Bayesian inference, are specific for each task or subserve multiple tasks. Current approaches cannot distinguish between these two possibilities because they cannot extract comparable representations across different tasks. Here, we develop a novel method, termed cognitive tomography, that can extract complex, multidimensional priors across tasks. We apply this method to human judgments in two qualitatively different tasks, “familiarity” and “odd one out,” involving an ecologically relevant set of stimuli, human faces. We show that priors over faces are structurally complex and vary dramatically across subjects, but are invariant across the tasks within each subject. The priors we extract from each task allow us to predict with high precision the behavior of subjects for novel stimuli both in the same task as well as in the other task. Our results provide the first evidence for a single high-dimensional structured representation of a naturalistic stimulus set that guides behavior in multiple tasks. Moreover, the representations estimated by cognitive tomography can provide independent, behavior-based regressors for elucidating the neural correlates of complex naturalistic priors.
58. A Scalable Gibbs Sampler for Probabilistic Entity Linking
Authors: Neil Houlsby, Massimiliano Ciaramita
First appeared: 2013-09-02
Venue: European Conference on Information Retrieval (ECIR), 2014
Full paper
► Abstract
Entity linking involves labeling phrases in text with their
referent entities, such as Wikipedia or Freebase entries. This task is challenging due to the large number of possible entities, in the millions, and
heavy-tailed mention ambiguity. We formulate the problem in terms of
probabilistic inference within a topic model, where each topic is associated with a Wikipedia article. To deal with the large number of topics
we propose a novel efficient Gibbs sampling scheme which can also incorporate side information, such as the Wikipedia graph. This conceptually
simple probabilistic approach achieves state-of-the-art performance in
entity-linking on the Aida-CoNLL dataset.
59. Active learning for Interactive Visualization
Authors: Tomoharu Iwata, Neil Houlsby, Zoubin Ghahramani
First appeared: 2013-05-29
Venue: International Conference on AI and Statistics (AISTATS), 2013
Full paper
► Abstract
Many automatic visualization methods have been proposed. However, a visualization that is automatically generated might be different to how a user wants to arrange the objects in visualization space. By allowing users to re-locate objects in the embedding space of the visualization, they can adjust the visualization to their preference. We propose an active learning framework for interactive visualization which selects objects for the user to re-locate so that they can obtain their desired visualization by re-locating as few as possible. The framework is based on an information theoretic criterion, which favors objects that reduce the uncertainty of the visualization. We present a concrete application of the proposed framework to the Laplacian eigenmap visualization method. We demonstrate experimentally that the proposed framework yields the desired visualization with fewer user interactions than existing methods.
60. Experimental Adaptive Bayesian Tomography
Authors: Konstantin Kravtsov, Stanislav Straupe, Igor Radchenko, Gleb Struchalin, Neil Houlsby, Sergey Kulik
First appeared: 2013-03-07
Venue: Phyiscal Review A
Full paper
► Abstract
We report an experimental realization of an adaptive quantum state tomography protocol. Our method takes advantage of a Bayesian approach to statistical inference and is naturally tailored for adaptive strategies. For pure states we observe close to 1/N scaling of infidelity with overall number of registered events, while best non-adaptive protocols allow for 1/\sqrt{N} scaling only. Experiments are performed for polarization qubits, but the approach is readily adapted to any dimension.
61. Collaborative Gaussian Processes for Preference Learning
Authors: Neil Houlsby, Ferenc Huszár, Jose M. Hernández-lobato, Zoubin Ghahramani
First appeared: 2012-12-03
Venue: Neural Information Processing Systems (NeurIPS), 2012
Full paper
► Abstract
We present a new model based on Gaussian processes (GPs) for learning pairwise preferences expressed by multiple users. Inference is simplified by using a \emph{preference kernel} for GPs which allows us to combine supervised GP learning of user preferences with unsupervised dimensionality reduction for multi-user systems. The model not only exploits collaborative information from the shared structure in user behavior, but may also incorporate user features if they are available. Approximate inference is implemented using a combination of expectation propagation and variational Bayes. Finally, we present an efficient active learning strategy for querying preferences. The proposed technique performs favorably on real-world data against state-of-the-art multi-user preference learning algorithms.
62. Adaptive Bayesian Quantum Tomography
Authors: Ferenc Huszár, Neil Houlsby
First appeared: 2012-07-05
Venue: Physical Review A
Full paper
► Abstract
In this letter we revisit the problem of optimal design of quantum tomographic experiments. In contrast to previous approaches where an optimal set of measurements is decided in advance of the experiment, we allow for measurements to be adaptively and efficiently re-optimised depending on data collected so far. We develop an adaptive statistical framework based on Bayesian inference and Shannon's information, and demonstrate a ten-fold reduction in the total number of measurements required as compared to non-adaptive methods, including mutually unbiased bases.
63. Bayesian Active Learning for Classification and Preference Learning
Authors: Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, Máté Lengyel
First appeared: 2011-12-24
Venue: arXiv, 2011
Full paper
► Abstract
Information theoretic active learning has been widely studied for probabilistic models. For simple regression an optimal myopic policy is easily tractable. However, for other tasks and with more complex models, such as classification with nonparametric models, the optimal solution is harder to compute. Current approaches make approximations to achieve tractability. We propose an approach that expresses information gain in terms of predictive entropies, and apply this method to the Gaussian Process Classifier (GPC). Our approach makes minimal approximations to the full information theoretic objective. Our experimental performance compares favourably to many popular active learning algorithms, and has equal or lower computational complexity. We compare well to decision theoretic approaches also, which are privy to more information and require much more computational time. Secondly, by developing further a reformulation of binary preference learning to a classification problem, we extend our algorithm to Gaussian Process preference learning.